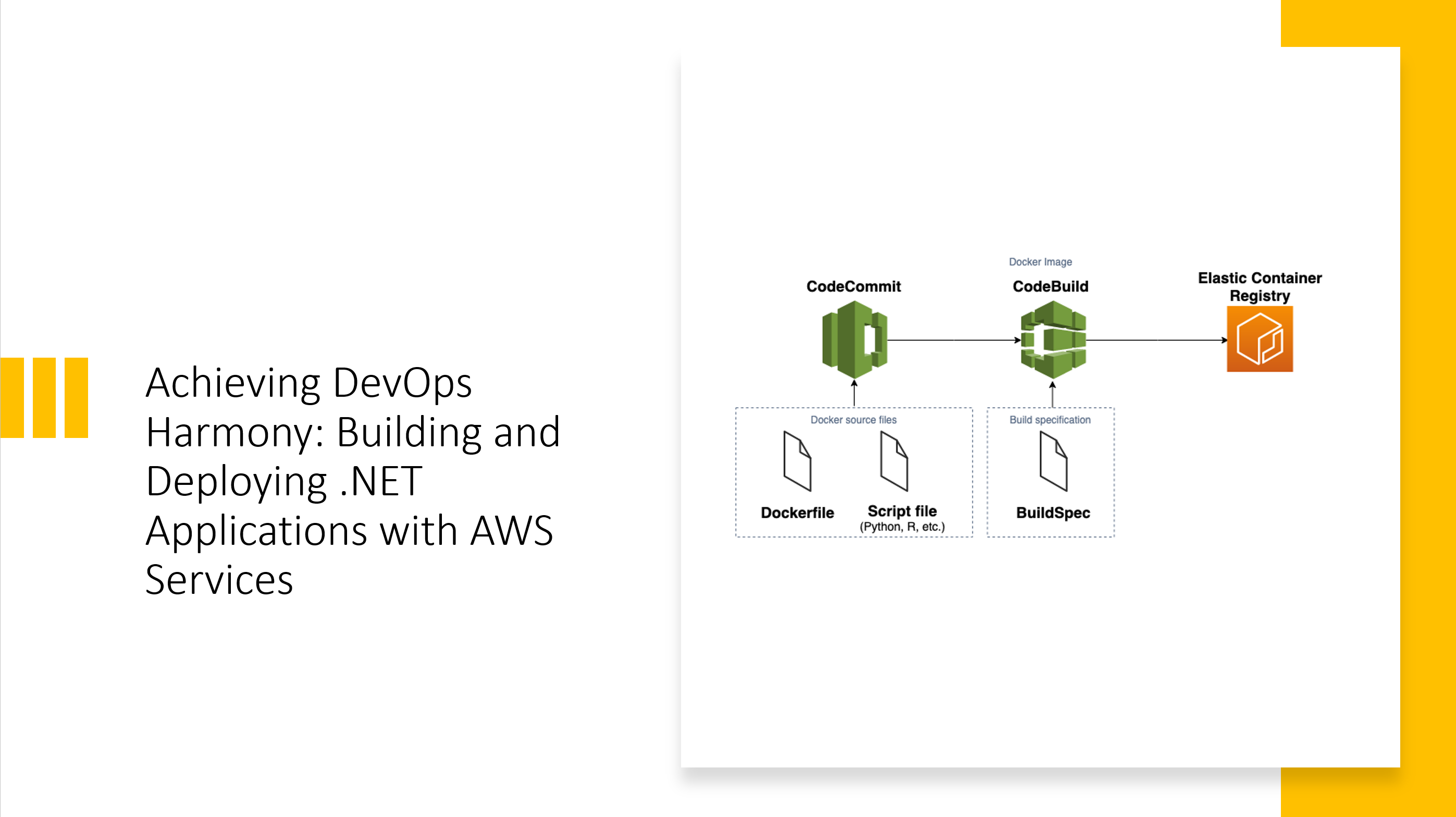
Scaling Up Your Pods: How Horizontal Pod Autoscaling Wins

In the dynamic world of containerized applications, ensuring your deployments can handle fluctuating workloads is crucial. Kubernetes offers built-in mechanisms for scaling, and while replica sets are a foundational tool, horizontal pod autoscaling (HPA) takes it a step further. This…
Read more