Cloud Computing
Nithin Mohan TK
March 14, 2024

In the dynamic world of containerized applications, ensuring your deployments can handle fluctuating workloads is crucial. Kubernetes offers built-in mechanisms for scaling, and while replica sets are a foundational tool, horizontal pod autoscaling (HPA) takes it a step further. This…
Read more
AWS, Azure, Azure Kubernetes Service(AKS), Cloud Computing, Cloud Native, Cloud Native Computing Foundation, Elastic Kubernetes Service(EKS), Emerging Technologies, Kubernates, Kubernetes, OpenSource
Nithin Mohan TK
December 16, 2023
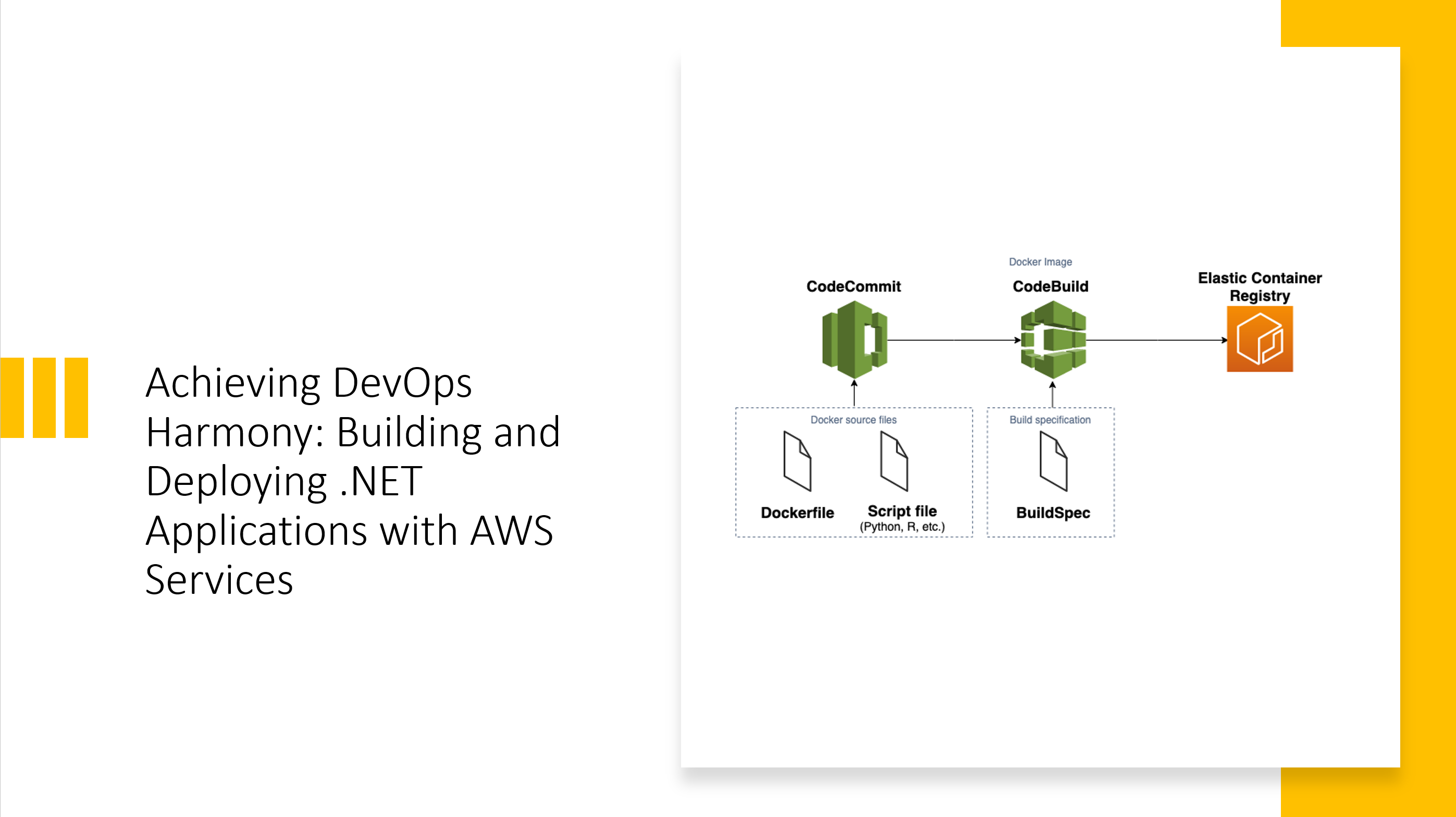
Introduction In the fast-paced world of software development, efficient and reliable CI/CD pipelines are essential. In this article, we’ll explore how to leverage AWS services—specifically AWS CodeCommit, AWS CodeBuild, AWS CodePipeline, and Amazon Elastic Container Registry (ECR)—to build, test, and…
Read more
Amazon, AWS, AWS CodeBuild, AWS CodeCommit, AWS CodeDeploy, AWS CodePipeline, Cloud Computing, Elastic Compute Service(EC2), Elastic Container Registry(ECR), Elastic Kubernetes Service(EKS), Emerging Technologies, Platforms
Nithin Mohan TK
November 11, 2023

Introduction: Infrastructure as Code (IaC) has revolutionized the way developers provision and manage cloud resources. Among the plethora of tools available, AWS Cloud Development Kit (CDK) stands out for its ability to define cloud infrastructure using familiar programming languages like…
Read more
Nithin Mohan TK
October 29, 2023

Introduction: Amazon Elastic Kubernetes Service (EKS) simplifies the process of deploying, managing, and scaling containerized applications using Kubernetes on AWS. In this guide, we’ll explore how to provision an AWS EKS cluster using Terraform, an Infrastructure as Code (IaC) tool….
Read more
Amazon, AWS, Cloud Computing, Containers, Elastic Container Registry(ECR), Elastic Kubernetes Service(EKS), Emerging Technologies, Kubernates, Kubernetes, Orchestrator, PaaS
Nithin Mohan TK
October 28, 2023
Introduction: Amazon Elastic Container Registry (ECR) is a fully managed container registry service provided by AWS. It enables developers to store, manage, and deploy Docker container images securely. In this guide, we’ll explore how to provision a new AWS ECR…
Read more
Nithin Mohan TK
October 21, 2023
In the fast-paced world of technology, ensuring the reliability of services is paramount for businesses to thrive. Site Reliability Engineering (SRE) has emerged as a discipline that combines software engineering and systems administration to create scalable and highly reliable software…
Read more