When Amazon announced the Nova family of foundation models at re:Invent 2024, the enterprise architecture community reacted with a mixture of intrigue and practical hesitation. Until that point, Amazon Bedrock was primarily understood as a model aggregator—the best place to securely consume Anthropic’s Claude 3.x, Meta’s Llama, and Cohere. The introduction of first-party flagship models (Micro, Lite, Pro, and Premier) signaled a strategic shift. Would Nova rival the reasoning depth of Claude Sonnet? Would it outprice Llama 3? Was it a hedge against third-party dependency, or a genuine frontier alternative?
Now, 15 months later, in early 2026, the data from production enterprise deployments is in. The hype has settled into operational reality. We have benchmarked the latency, scrutinized the multi-modal extraction capabilities against dense PDFs, and reconciled the billing statements across multi-agent orchestrations. This article is the honest, practitioner-led retrospective of the Amazon Nova model family: where they completely dominate the cost-performance curve, where they fall explicitly short of Claude Sonnet 4.x, and the precise architectural patterns you should use today to deploy them.
The Nova Family Spectrum: From Micro to Premier
The defining characteristic of the Nova family is its brutal tiering. AWS did not just release “a model;” they released a multi-modal spectrum engineered specifically for architectural model-routing in enterprise pipelines.
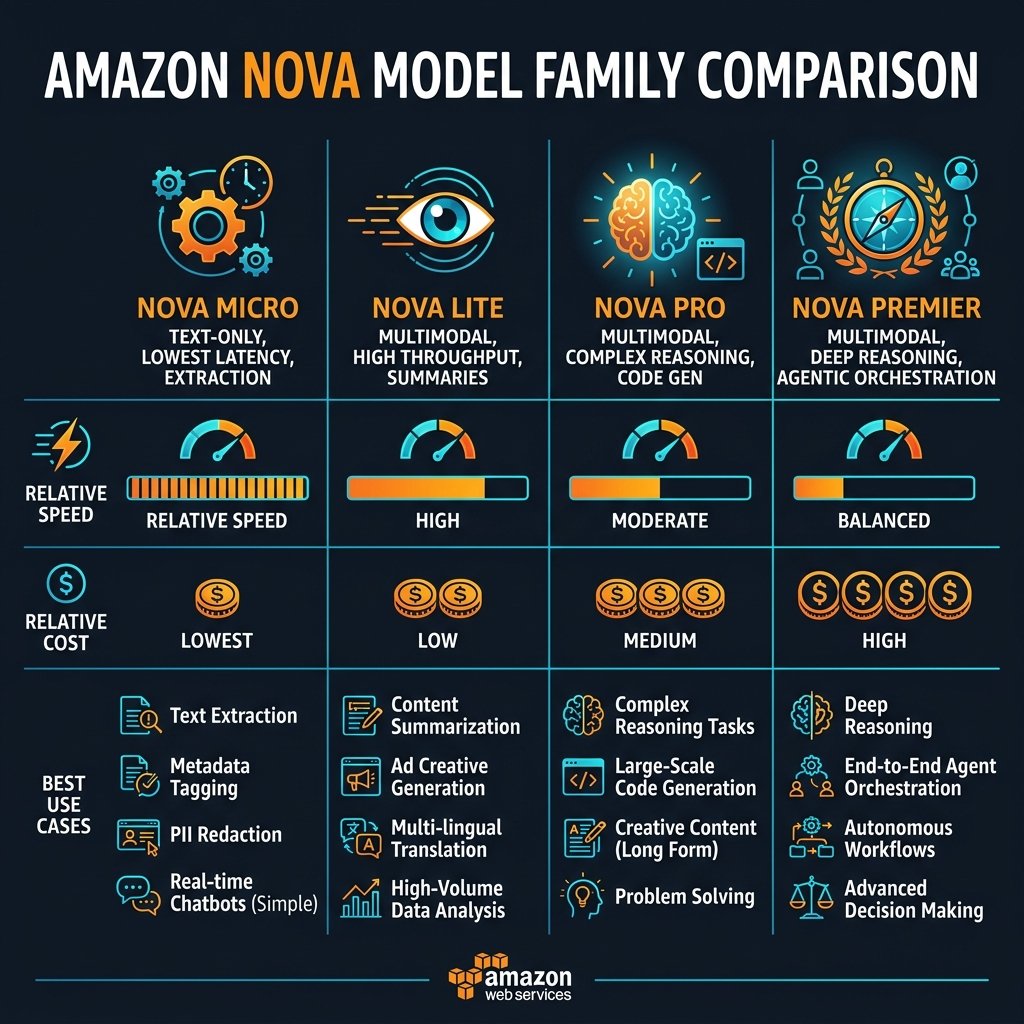
Nova Micro: The Latency Champion
Nova Micro is text-only, and its entire existence is justified by latency and cost. In our benchmarks, Nova Micro consistently delivers Time to First Token (TTFT) sub-150ms and token generation speeds that rival pure deterministic APIs. It is not designed to write Shakespeare or orchestrate React applications. It is engineered to perform rapid classification, sentiment analysis, entity extraction, and intent routing.
In production, we use Nova Micro almost exclusively as a Semantic Router. In a multi-agent system, the initial user query hits Nova Micro first. Micro evaluates the query, decides which downstream heavy model (or specific API) holds the domain context, and forwards it. At a fraction of the cost of larger models, adding this Micro routing hop adds negligible latency and saves thousands of dollars by preventing simple queries from waking up Nova Premier or Claude Sonnet.
import boto3
import json
bedrock_runtime = boto3.client('bedrock-runtime', region_name='us-east-1')
def route_query_with_nova_micro(user_query: str) -> str:
"""
Uses Nova Micro strictly for rapid semantic classification.
Expect TTFT ~100-150ms. High throughput, lowest cost.
"""
system_prompt = """You are a router. Classify the user query into ONE of these categories:
[BILLING, TECHNICAL_SUPPORT, SALES, REFUND, OTHER].
Output ONLY the category name as a single word."""
body = {
"schemaVersion": "messages-v1",
"messages": [
{"role": "user", "content": [{"text": user_query}]}
],
"system": [{"text": system_prompt}],
"inferenceConfig": {
"maxTokens": 10,
"temperature": 0.0 # Zero creativity for deterministic routing
}
}
response = bedrock_runtime.invoke_model(
modelId="amazon.nova-micro-v1:0",
contentType="application/json",
accept="application/json",
body=json.dumps(body)
)
result = json.loads(response['body'].read())
return result['output']['message']['content'][0]['text'].strip()
Nova Lite and Pro: The Multimodal Workhorses
Nova Lite and Nova Pro are where the architectural bulk of enterprise tasks live. Both are multimodal—capable of directly digesting images, charts, audio, and dense PDFs without requiring an intermediary OCR layer like Textract.
Nova Lite is the unsung hero of pipeline document processing. We found that for extracting data from scanned invoices, receipts, and standard structured PDFs, Nova Lite achieves 95% of the accuracy of Nova Pro at significantly lower inference costs. It has become our default engine for high-volume IDP (Intelligent Document Processing) pipelines where the structural layout matters, but deep inferential reasoning is not needed.
Nova Pro is the Claude 3.5 Haiku competitor. It is the general-purpose, balanced model. It writes solid Python code, handles complex RAG (Retrieval-Augmented Generation) contextualization over 50+ document pages seamlessly, and maintains conversational awareness beautifully. If you are building a standard enterprise Q&A chatbot to sit on top of a company intranet, Nova Pro is the default starting point.
Nova Premier: The Orchestrator
Nova Premier is Amazon’s frontier model, designed to compete with Claude Sonnet/Opus and GPT-4. It is significantly more expensive but possesses deep reasoning, advanced tool use (Function Calling), and complex systemic logic.
The reality check: As of Q1 2026, for extreme mathematical reasoning, complex legacy code refactoring, or zero-shot deep coding tasks, Anthropic’s Claude Sonnet series still maintains an edge over Nova Premier. However, Nova Premier has a distinct AWS-native advantage: it has been heavily fine-tuned for AWS API orchestration and integration with Bedrock Agents. If your primary use case involves an agent writing SQL, deciding when to lookup a DynamoDB table, or executing Step Functions, Nova Premier’s function-calling reliability is top-tier.
The Model Tiering Architecture: Composing the Nova Family
Deploying a single model for all enterprise tasks is an architectural failure pattern in 2026. If you use Nova Premier to summarize a receipt, you are burning capital; if you use Nova Micro to write a multi-threaded C# application, you will burn engineering goodwill.
The prevailing pattern is Model Tiering. Because all Nova models use the exact same Bedrock Converse API payload schema (`messages-v1`), hot-swapping models programmatically is trivial.
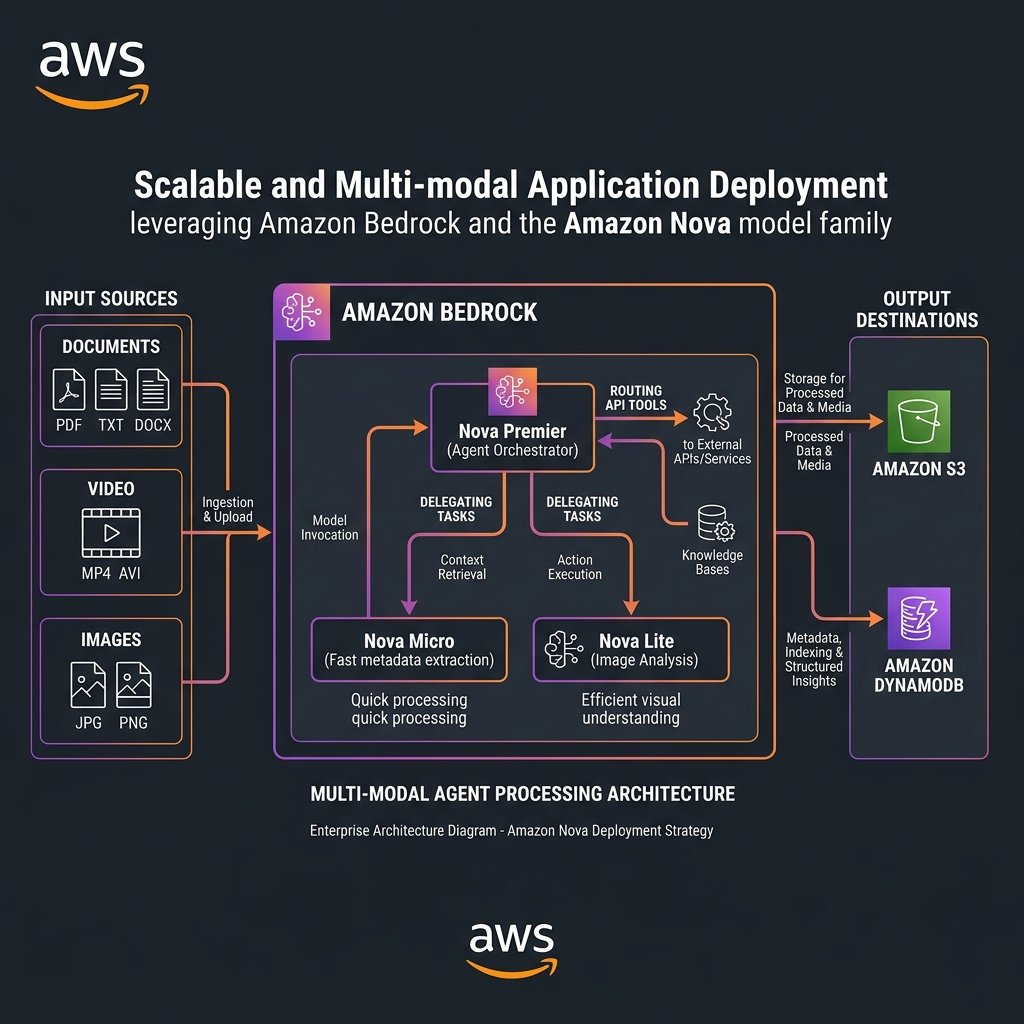
flowchart TD
U["User Request"] --> R{"Router Agent (Nova Micro)"}
R -->|"Data Extraction"| L["Document Processor (Nova Lite)"]
R -->|"Standard Chat/RAG"| P["Intranet Chatbot (Nova Pro)"]
R -->|"Complex Action"| PR["Action Orchestrator (Nova Premier)"]
L --> DB[("Vector DB")]
P --> DB
PR --> API("Backend APIs")
API --> PR
PR --> OUT["Final Response"]
P --> OUT
L --> OUTIn this architecture, Nova Micro serves as the gateway infrastructure. It takes the user intent and delegates it. By isolating the API orchestration to Nova Premier, we contain the high token costs to ONLY the queries that actively mutate data or require multi-step reasoning.
Enterprise Compliance, Fine-Tuning, and Canvas Integrations
A significant driver for adopting Amazon Nova models over external proprietary models is the integration with AWS’s broader security and machine learning ecosystem.
Bedrock Custom Model Import and Fine-Tuning
While Prompt Engineering and RAG solve 90% of enterprise problems, the remaining 10%—speaking in a highly specific corporate voice, recognizing esoteric internal part numbers, or adapting to stringent regulatory formats—requires model fine-tuning. Amazon Nova models support customized fine-tuning directly within Bedrock using your proprietary data residing securely in S3. Because Nova is a first-party model, the pricing for customized provisioned throughput on specialized Nova models is generally more favorable than provisioned throughput for specialized third-party frontier models.
Multimodal Input Limits: The 20-Minute Video Problem
Nova Lite and Nova Pro support direct video ingestion (with audio). You can literally pass an S3 URI of an MP4 into the model and ask, “Give me a timestamped summary of when the presenter shows the new UI.” However, as of early 2026, there are strict duration and size limits on video context windows to prevent unbounded GPU memory allocation. If you are uploading 2-hour Zoom recordings direct to Nova, the API will reject it. You still need an upstream Lambda function utilizing MediaConvert or FFMPEG to chunk large video payloads into manageable clips before piping them into the Bedrock Converse API.
Implementing Multi-Modal Reasoning with Nova Pro
To understand how multimodal input behaves via the API, here is a standard pattern for passing both a user instruction and an image buffer directly to Nova Pro for visual extraction:
import boto3
import base64
import json
bedrock_runtime = boto3.client('bedrock-runtime', region_name='us-east-1')
def analyze_architecture_diagram(image_path: str, prompt: str) -> str:
"""
Passes a local image directly into Nova Pro for multimodal reasoning.
No Textract or OCR needed.
"""
with open(image_path, "rb") as image_file:
encoded_string = base64.b64encode(image_file.read()).decode("utf-8")
body = {
"schemaVersion": "messages-v1",
"messages": [
{
"role": "user",
"content": [
{
"image": {
"format": "png",
"source": {"bytes": encoded_string}
}
},
{
"text": prompt
}
]
}
],
"inferenceConfig": {
"maxTokens": 1000,
"temperature": 0.2
}
}
response = bedrock_runtime.invoke_model(
modelId="amazon.nova-pro-v1:0",
contentType="application/json",
accept="application/json",
body=json.dumps(body)
)
result = json.loads(response['body'].read())
return result['output']['message']['content'][0]['text']
# Usage:
# result = analyze_architecture_diagram(
# "serverless_arch.png",
# "List all the AWS services present in this diagram and suggest potential single points of failure."
# )
The TCO Equation: When to Use Nova vs Claude
At an architectural level, deciding between Amazon Nova and Anthropic’s Claude (both hosted securely inside Bedrock) comes down to a strict Total Cost of Ownership (TCO) evaluation mapped to capability ceilings.
- For 85% of general enterprise tasks (RAG summarization, document extraction, basic conversational bots), Nova Pro and Lite provide indistinguishable output quality from their Claude counterparts at a significantly reduced token cost profile. By migrating these workloads to Nova, enterprises drastically lower their monthly Bedrock burn rate.
- For extreme context windows, Claude still maintains specific advantages. While Nova handles dense documents well, Claude’s massive context window and prompt-caching features remain the gold standard for querying against entire codebases or 600-page legal discovery datasets in a single prompt.
- For elite frontier reasoning (e.g., zero-shot complex algorithm design in Rust, or orchestrating an agent that writes infrastructure-as-code and corrects its own terraform errors), Claude Sonnet 4.x remains the undeniable leader. Teams should route these highly specific, difficult technical cognitive tasks to Claude, while letting Nova handle the routine, high-volume orchestration surrounding it.
The beauty of the ecosystem is that you no longer have to choose. A master-routed Bedrock architecture utilizes Nova Micro to direct traffic, Nova Lite to extract documents at scale, and escalates to Claude Sonnet only when deep semantic mastery is required. That is the architecture of a cost-optimized 2026 GenAI platform.
Key Takeaways
- The Nova family is engineered for Model Tiering. Do not apply Nova Premier to every problem. Exploit the speed of Nova Micro for routing and the cost-efficiency of Nova Lite for standard data extraction.
- First-Party Economics. Because AWS controls the underlying stack, Nova models offer highly competitive provisioning costs and deep native integrations with AWS features like Custom Model Import and Bedrock Knowledge Bases.
- Multimodal out of the box. Nova Lite and Pro natively ingest images, audio, and video, replacing external OCR and transcription pipelines for routine data. Be mindful of input size/duration limits for heavy media.
- Unified API simplifies migration. By using the Bedrock `messages-v1` (Converse API) schema, swapping between Nova models, or escalating tasks to Anthropic’s Claude, requires literally zero codebase refactoring.
- AWS Security Posture applies entirely. Custom data utilized via Nova endpoints remains inside your VPC boundaries, covered by KMS encryption, and is definitively excluded from future base model training sets.
Glossary
- Amazon Nova Family
- A suite of state-of-the-art, multi-modal foundation models developed by AWS, consisting of Micro, Lite, Pro, and Premier variants, designed to cover the entire latency-to-reasoning spectrum.
- Model Tiering
- The architectural practice of using specialized, lightweight models (like Nova Micro) to initially evaluate and route tasks, before escalating strictly complex workloads to heavier, more expensive frontier models (like Nova Premier or Claude Sonnet).
- Time To First Token (TTFT)
- A crucial latency metric defining the milliseconds it takes for an LLM to begin streaming its response after receiving the API payload. Important for real-time user interfaces.
- Semantic Router
- An LLM implementation (usually utilizing a very fast model like Nova Micro) configured solely to analyze a user query and determine which downstream tool, database, or heavier model should actually handle it.
- Converse API
- The unified payload structure (`messages-v1`) introduced in Amazon Bedrock that standardizes the JSON format across models (Nova, Claude, Llama, etc.), removing the need for model-specific serialization logic.
References & Further Reading
- → Amazon Nova Model Overview— Official AWS capability metrics, model parameters, and recommended workload alignments for the Nova family.
- → Amazon Nova API Reference— Technical documentation mapping the Converse API payload to Nova-specific multimodal features.
- → AWS Launch Blog: Introducing Amazon Nova— The foundational re:Invent 2024 announcement detailing the strategic tiering of Micro, Lite, Pro, and Premier.
- → Amazon Bedrock Custom Model Fine-Tuning— Documentation covering the deployment of proprietary data fine-tuning on top of the base Amazon Nova foundations.
Discover more from C4: Container, Code, Cloud & Context
Subscribe to get the latest posts sent to your email.